序
この記事は題材としてアダルトコンテンツに関わる内容を多分に含む。
DLsite Voice Utilsは私が開発、OSSとして公開しているユーティリティプログラムである。
このソフトウェアは自身でも常用していることから発展を続けており、初期には実装していなかった機能や、あえて実装しなかった機能を含め当時よりかなり多くのことができるようになっている。
このソフトウェアの発展はたびたび記事にはしているが、基本的に発展要素のロジックを中心に解説しているため、そろそろこのソフトウェア自体のベネフィットの説明が難しくなってきた。
そこで、本記事では2024年11月時点でのDLsite Voice Utilsを改めて紹介する。 音声作品を愛好する人はもちろん、技術的観点からも興味深いことだろう。
ソフトウェア概要
DLsite Voice Utilsはその名の通り、DLsiteで数多く販売されている「えっちなASMR」(通称「音声作品」)のコンテンツ管理をするための「専用検索エンジン」の一種である。 コンテンツ管理といってもデータのダウンロード、展開、データ入力などはユーザーの好きな環境で行えるため、基本的に提供されるのは
- 聴くときにコンテンツを探すためのユーティリティ
- コンテンツを整理するためのルールとメソッド
である。
加えて、Vociestatという機能があり、自分の中の好みや流行から作品購入時の判断材料にすることができる。 これがまぁまぁのオーバーテクノロジーになっているのも特徴のひとつ。
別に「えっちなASMR」である必要はまったくないのだが、
- サークル
- キャスト
- カバーアート
が主要な要素であるため、応用はあまり効かない。 例えば、音楽においてサークルをレーベルに置き換え、キャストをアーティストに置き換えることで応用できるかもしれないが、そんなに便利でもないと思う。 なぜならば、音楽に関してはAlbum, Artist, AlbumArtistといったメタデータを扱う音楽プレイヤーのほうが利便性が高いからだ。
音楽プレイヤーじゃ駄目なの?
まず、一般的に音声作品のオーディオトラックはちゃんとメタデータが入っていない。 音楽プレイヤーで再生しようとすると、前提として音声作品のメタデータをちゃんと埋める必要があるし、よくある複数フォーマットが収録されているタイプはフォーマットをひとつにしておかないとうまく動作しない。
そしてそうやって再生できるようにしたところで、音声作品を探す場合はカバーアートが重要になるけれど、音楽プレイヤーは探す主要な要素として使うほどカバーアートを重視していない。
さらに、作品を探す上で重要なのは作品の「属性」だが、ID3v2.4にもそのような属性を入れるのに適した項目はないし、入れたところでそれを有効に検索に使える音楽プレイヤーがそうそうない。
また、カバーアートの重要性の問題から音楽プレイヤーで再生するには再生表示の問題がある。 mpvやSMPlayerなどのほうが適性が高い。
総合的に見たときに、「使えないわけじゃないけど、不便」という感じになってしまうため、音声作品に最適化したほうが良いのだ。
「カスタム検索エンジン」の概念と価値
基本的にデータが少ないうちはフラットに名前つきで置かれていれば十分だが、量が増えてくると分類が必要になってくる。 増えたデータを管理するために階層ファイルシステムを用いてディレクトリ分けによって構造化して整理するのが一般的だ。
さらに増えてくると、分類に異なる角度を用いる必要が出てくる。
音楽であれば、通常アーティストとアルバム別にしていたところ、BPM別やジャンル別の分類が欲しくなるといったことだ。
Unix likeなOSのユーザーであればリンクファームによって仮想的に実現することができる。このような手法は、Linuxでは/dev/diskや/dev/mapperなどで使われている。
だがもはや自分でも把握できないほどに増えてくると、配置より検索が重要になってくる。 現状では最終的に「意図したものを発見できる検索」になる形だが、うまくいっているかどうかは別としてユーザーに見せるものをコントロールすることという手法のほうが最終段階とみなされている。 もっとも、それは明確な「欲しいもの」に到達できないため、実際の目的にはそぐわない。
検索したい対象によっては汎用的な手法で事足りる。
例えばテキストファイルであればfind, grepといったツールによって欲しいものを見つけ出すことができる。
また、音楽ファイルのように探す方法が確立されているようなものは、すでにそれを実現するためのソフトウェアがあったりする。
だが、探したい情報がファイル自体に存在していない場合はなかなか難しい。 典型的なのが動画ファイルであり、「“こんな感じ” の動画はどこだっけ」という探し方をするのはかなり難しい。 同様に、画像データも「Johnと出かけたときに撮った写真はどれだっけ」のような探し方をするのは難しい。
webサービスであれば、集合知方式である程度補うことができるが、ローカルにあるファイルだと探したい対象情報は自分で付与しないとどこにもないため、単純な検索手法で見つけ出すのはより難しい。
そこで探したい対象に特化したカスタム検索エンジンの自作、という話になる。
「検索エンジン」と言うとGoogleのようなものをイメージする人も多いが、あれは「web検索エンジン」として作られており、webという対象に特化した作りをしている。 探したい対象が異なるのであれば、異なる目的のものに寄せる必要は全くない。
また、自身が使うためのカスタム検索エンジンを作るときは任意の前提を導入できるというのが大きい。 検索エンジンを成立させるには
- 検索手法の確立
- 検索対象データの付与
- 検索ソフトウェアの開発
という3つが必要になるが、ここで好きなだけ制約を導入したり前提条件を設定したりすることができるため、汎用のものを作るのと比べて難易度が全く異なるものにできる。
「自分用にカスタム検索エンジンを作る」というのはプログラミング難易度としても高くない上に、ソフトウェアというものを考えるのには良い題材であるため、プログラミング初中級者にも結構おすすめだ。
ソフトウェアの基本構成
最終的にインターフェイスになるものは、index.htmlとapp.jsのふたつのファイルである。
つまりはwebアプリケーションであり、SPAであるが、file:///プロトコルで動作するようになっており、完全なオフラインSPAである。
index.htmlの任意のウェブブラウザで開くことで実行できる。基本的には、ファイルブラウザからindex.htmlをダブルクリックである。
これらのデータ部分としてmeta.js, soundindex.jsのふたつのJavaScriptファイルをロードする。
また、あらかじめ固定で用意しておくファイルとしてconfig.jsも読むが、これはDLsite Voice Utils単体で使う場合は名前を定義するだけで中身はいらないものである。
meta.jsとsoundindex.jsはmkjson.rbスクリプトが生成する。
mkjson.rbは各種のファイル配置とmeta.yamlファイルからこれらを生成する。
meta.yamlファイルは手で編集するものだが、mkmeta.rbスクリプトが作品ごとのデータを自動的に追加する。
また、付属するユーティリティによって作品単体にフォーカスして編集することができる。
これはedit-dlvoice.rbというスクリプトだが、edit-dlvoice.nemo_actionというNemo Actionsファイルが付属するため、Nemoを使っていれば右クリックから現在開いている作品のデータを編集できるようになっている。
index.htmlには作品が列挙され、作品をクリックすることでdlvfol://というカスタムスキーマによってそのパスが開かれる。
カスタムハンドラを設定していれば、ファイルブラウザなどで開くことができる。
最近、config.jsでfile://を使うこともできるようになった。
要求されるデータ配置は少し複雑で、同一階層にVoice, _VoiceByCast, _VoiceLibrary(このソフトウェア)の3つのディレクトリを用意する必要がある。
作品はVoice/作品名, Voice/_サークル名/作品名, Voice/_サークル名/_シリーズ名/作品名のいずれかの配置にする必要がある。
作品名フォルダより下のファイル配置は自由。
_VoiceByCast以下は_VoiceByCast/キャスト名/作品名 -> 作品, _VoiceByCast/キャスト名/_サークル名 -> サークル, _VoiceByCast/キャスト名/__シリーズ名 -> シリーズのいずれかの形でシンボリックリンクを貼る。
さらに、サークル名は_[よみがな]_サークル名の形で、キャスト名は[よみがな]_キャスト名の形でよみがなを振ることもできる。これは選択項目の並びに影響する。
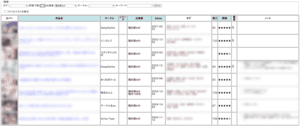
index.htmlで表示されるサムネイル画像は、作品フォルダのthumb.jpgファイルである。
「JavaScriptファイルのデータベース」の適切性
私の手元にあるmeta.jsのサイズは1.4MBほどあるが、Node.jsでこれを解釈させるのにかかる時間は0.01秒未満である。
また、ロードしたときのメモリ上のサイズもこれに準ずるものと思えば良いが、今どきのコンピュータにおいて数MBのメモリ消費など塵芥だろう。
私の場合総作品数は500作品程度だが、仮に1作品400円としても1000作品で40万円、10000作品で400万円ほどかかる計算であるため、個人所有の作品で1000000レコードとかになる可能性はないと考えて良いだろう。 このため、意外と大きなデータでも通用する方法である。 実際のところ、ローカルなら1000000レコードでも全然やれる。
結局全体のデータを取得するのであればそのデータをメモリに格納する必要があるため、必要なメモリ容量は結局変わらない。 これをサーバーと分離したとしても、サーバーが同一ホストなのであれば結局ファイルの形で直接取得するJSONが一番小さい。
さらにデータロードという観点からいっても、JavaScript処理系にとってオブジェクトリテラルの解釈というのは猛烈に速いものなので、どんなデータベースを使うよりも圧倒的にロードが速い。
ここでJSON.parse()を使っているのではなく、HTMLのscript要素を使ってロードしているというのがまたさらに速くなる要素である。
もちろん、データを部分的に取得したい場合は使えないし、使うデータが部分的であれば最も良いとも限らないが、データを全体から検索したいといった場合には簡単なだけでなくベストな方法ですらある。
meta.jsなどはvar meta =という行とJSONを組み合わせたものだが、これは安全に成立する。
まず、JSONは「閉じたJavaScriptコード」である。 つまり、オブジェクトリテラルを書ける場所であれば、前後に何があろうとも正しくオブジェクトリテラルとして解釈される。
そして、JavaScriptの文法として、複数のホワイトスペースは圧縮され、そこに改行が含まれ、かつ連続して解釈できない場合だけ文を区切るようになっている。だから
if
(foo)
{}とか
ary.push
(something)みたいなのはちゃんとvalidなコードである。
「JSONがオブジェクトリテラルとして安全に置ける」というルール上、
"var meta = " + jsonはちゃんと安全に有効なJavaScriptコードにできるし、文がつながるのならホワイトスペースが入るところに改行を入れても構わないので、
"var meta = \n" + jsonも同様に安全に有効なJavaScriptコードにできる。 1行目を除去すればJSONとしてパースできるので、改行を入れるとちょっと便利になる。
項目と検索
表の中に含まれる項目は
- カバーアート (ファイル配置)
- 作品名 (ファイル配置)
- サークル名 (ファイル配置)
- シリーズ名 (ファイル配置)
- 出演者 (ファイル配置)
- btime (
mkmeta.rbが生成) - タグ (入力)
- 長さ (入力)
- 評価 (1〜5) (入力)
- 概要 (入力 /
mkjson.rbが自動補完) - ノート (入力)
- ファイル一覧 (
mkjson.rbが生成)
である。
ここから
- タグ (選択式)
- 評価下限
- 出演者 (選択式)
- サークル (選択式)
- フリーワード
で絞り込みができる。

また、
- 作品名
- サークル
- シリーズ
- 出演者
- btime
- 長さ
- 評価
で並び替えもできる。
LWMP (LocalWebMediaPlayer) との連携
LWMP (Local Web Media Player)は音声・動画ファイルをブラウザを使って再生するためのローカルネットワーク向けのソフトウェアである。
複数ホストがLAN内にある(PCとスマホというケースも含む)環境向けで、他ホストでメディアファイルを再生するためのものだ。 フォルダ再生とm3uプレイリストに対応している。
これを作った最大の理由はメインPC上にある音楽をスマホで聴きたいからだが、フォルダ再生に対応しているため音声作品を聴くのにも結構向いている。 音声作品はデータサイズ的にスマホに入れるのは厳しいし、しかしスマホで聴きたい(というか、PCに縛られたくない)ことは結構あるので、音声作品の再生とも相性は結構いい。
だがそもそもファイル数が多すぎて探すのが大変だからDLsite Voice Utilsを作ったわけで、単にディレクトリを配信するだけでは利便性はだいぶ低い。
そこでDLsite Voice Utilsになるわけだが、DLsite Voice Utilsがdlvfol://を使うようになったのは、「ブラウザで開くと扱いづらい、フォルダを開きたければカスタムハンドラが必要」ということによる。
つまり、LWMPで開くようにすればここの部分をシームレスにつなぐことができる。
このため、DLsite Voice UtilsはLWMPと連携して利用することができるようになっている。
これは、config.jsでLWMPのアドレスを設定し、index.htmlをwebサーバーで配信するだけである。
LWMPはLighttpdを必要とするため、index.htmlの配信もLighttpdを使うのがおすすめ。
さすがにNemo Actionsでのデータベース編集などもあることからローカルで再生する分にはLWMPなしで使ったほうが使い勝手は良いが、リモートで再生できるようになるのは活用の幅が広がって良い。
VoiceStat
VoiceStatは現在のデータの統計情報と、推測される「好み」「流れ」を提示するものである。
現在は作りの違いからvoicestat.rbとvoicestat2.rbに分かれているが、いずれvoicestat2.rbに統一してそれがvoicestat.rbになる予定である。
現在提示される項目は
- キャストの作品数
- サークルの作品数
- キャストの平均スコア
- サークルの平均スコア
- ☆5作品一覧
- ☆5キャスト一覧
- ☆5サークル一覧
- 総作品数
- 全体の平均スコア
- 平均の長さ
- スコアをつけていない作品数
- 評価の高いキャスト ※
- 評価の高いサークル ※
- 最近評価の高いキャスト ※
- 最近評価の高いサークル ※
である。 ※のついている項目は、独自のアルゴリズムによって算出している。
VoiceStatはCLIスクリプトであり、ターミナルで実行・表示する。
この「独自のアルゴリズム」は結果的にはそれほど難しいことはしていないものの、それでもVoiceStatを求める理由と求められる度合いからすればだいぶオーバーテクノロジーである。
これは将来的な検証のためのものでもあり、今後もより「あるべき形」へと進んでいく予定だ。
その他の技法
バニラJavaScript SPA
LWMPもそうだし、いつものことではあるが、DLsite Voice Utilsもライブラリを何も用いないVanilla JavaScriptによるSPAとなっている。 といってもオフラインSPAであるためにHTTP通信やAPIコールがなく、その意味では普段ほどVanilla JavaScript JPAのハードルはない。
いつも言っていることだが、最近のウェブページはあまりにも重すぎる。 ページを開くとCPUコアを100%使うなんていうのは当たり前、メモリも数百MB使うのはザラ、エラーが出ていないページなんてほとんどない。
結局のところこれらは「必要なことを必要なだけする」ということができておらず、不必要なことでデバイスの足切りをしてリソースを無駄遣いし(SDGsにも背いて)、かつコードが制御できていないということだろう。
Vanilla JavaScript SPAはネタ扱いされることが多いが、実際は利益もとても多い。
プリミティブなDOM操作は直観的でないため苦手とする人が多いようだが、基本的な流れとやり方を覚えてしまえば簡単で意図せぬ問題を引き起こしにくい。
カスタムURLハンドラ
当然ながらウェブブラウザはdvlfol://などというスキームをサポートしていない。
だが、ウェブブラウザがネイティブに扱えない未知のスキームを取り扱うためのハンドラを登録する方法がある。
これは例えば、Zoomを開くとデスクトップアプリケーションのZoomで開こうとする、といった形で日頃目にするものである。
現代的なウェブブラウザは未知のスキームが与えられたとき、(許可されていれば)システムにそのリソースのオープンを依頼する。
Linuxシステムの場合、xdg-openに投げられ、Windowsであれば「開く」動作に投げられる。
Linuxの場合は
xdg-mime default dlsite_voice_folder.desktop x-scheme-handler/dlvfolのような形でスキームに対するデフォルトの.desktopファイルを関連づけることができる。
ちなみに、ハンドラにはリソースのURLが渡されるため、単純にnemo.desktopを指定するようなことはできない。
Nemoがdlvfol://というURLを理解できないためだ。
このため、dlsite_voice_folder.desktopが実行すdlvfol.zshは
#!/bin/zsh
xdg-open "file://${1##dlvfol://}"のようになっている。
ちなみにかなり見づらいが、やっていることとしてはJavaScriptで書くならば
"file://" + url.replace(/^dlvfol:\/\//, "")ようなことをしている。
つまり、file://のうしろに、URLからdlvfol://を取り除いたものを組み合わせているのだが、単純に置き換えでも表現可能だ。
その場合は
${url/dlvfol:\/\//file:\/\/}という表現になるが、バックスラッシュが多くてとても見づらいので##を使っている。
なお、##は#でも可能。今回のケースでは違いはない。
この方法で「DLsite Voice Utilsからフォルダを開く」が実現しているが、これはやや厳し目の制約を課していると言える。 システムに対してハンドラの登録が必要で、そのハンドラは自作しなければならないからだ。
だからこそLWMPとの連携は一般ユーザーにとってもいくらか親しみやすいものになる機能だ。 もっとも、サーバーでの配信が必要なため、そこまで優しいかは怪しいものだが。
利用する
前準備とデータ配置
- ライブラリディレクトリを用意する
- 各種ファイルを配置する起点になる
- 場所やディレクトリ名は任意
- ライブラリディレクトリ以下に
Voiceと_VoiceByCastディレクトリを作る ライブラリ/_VoiceLibraryとしてDLsite Voice Utilsを配置ライブラリ/_VoiceLibrary/dlsite_voice_utilsではない- リポジトリ名に対してリネームが必要
- 音声作品を
ライブラリ/Voice以下に配置- サークル+シリーズ -
ライブラリ/Voice/_サークル/_シリーズ/作品名 - サークル -
ライブラリ/Voice/_サークル/作品名 - サークル名なし -
ライブラリ/Voice/作品名
- サークル+シリーズ -
ライブラリ/_VoiceByCast/キャスト名ディレクトリをつくる- キャスト名ディレクトリの下に作品へのシンボリックリンクを作る
- サークル全作品に出演している場合は
_サークル名の形でサークルへのシンボリックリンクをつくる - シリーズ全作品に出演している場合は
__シリーズ名の形でシリーズへのシンボリックリンクをつくる - Windowsではシンボリックリンクを作るのに権限が必要なのでかなり面倒なはず
- サークル全作品に出演している場合は
データの生成
- (新しい作品を追加したとき)
_VoiceLibraryディレクトリでmkmeta.rbを実行 - (データを更新したとき)
_VoiceLibraryディレクトリでmejson.rbを実行
clientを使う
index.htmlをブラウザで開く
作品情報の更新
meta.yamlの当該作品の項目を更新する- Cinnamon/Nemoを使っている場合
edit-dlvoice.nemo_actionとedit-dlvoice.rbをNemo Actionsとして導入- 作品ディレクトリ以下で右クリック →
Edit database about this title - 更新して保存
LWMPとの連携
config.jsを設定voice_library_dirにライブラリディレクトリのパスを設定- 最後の
/を入れる必要がある - 実は現状、パスの長さしか使っていない
- 最後の
lwmp_serverにLWMPで配信するHTTPアドレスを設定
index.htmlをwebサーバーで配信- LWMPがLighttpdを必要とするため、Lighttpdを使うのが多分簡単
- 特にアドレスに制限はない
- LWMPで
Voiceディレクトリを配信