序
まずはこれを見てほしい。
これまでのChienomiは、私の環境だと700〜1000ms程度。 一般的なウェブサイトと比べれば速い方ではあるが、別に速くない。
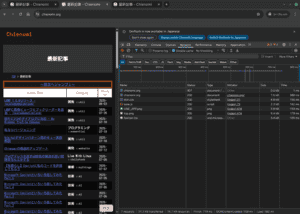
Chienomiは通信制限下でもサクサク表示の爆速ウェブサイトだったはずだ…… 思い出せ、爆速の心を……!
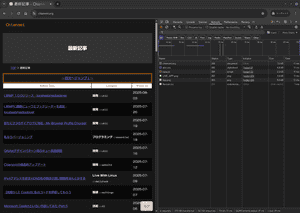
ちなみに、faviconが遅れているだけで、faviconナシならだいたい35msとかいう狂気の爆速of爆速である。 これは静的なウェブサイトとしても相当狂気の速さであり、CloudFlare経由だと1秒はかかるので30倍速い。 それどころか、かの「軽量・爆速」で知られる「阿部寛のホームページ」でも私の環境だと221msかかっている。 つまり、「阿部寛のホームページ」よりChienomiのほうが4倍速い。
実は単純な数字以上に狂気の速度な要素があるけれど、そこは後ほど説明する。
メインサーバーの移転という一大行事
メインサーバーはこれまでVultrのOsakaリージョンAMD High Performanceだった。 そこに至るまではConoHa VPS→さくらのVPSという変遷を経てVultrにたどり着いている。 この経緯はメインサーバーをさくらから転出、Vultrへ移転で述べている。
だが、ずっと「なんか通信がもっさり」というのが気になっていた。 速度自体は出ているが、通信の立ち上がりが悪く、SSHだと入力がラグいので特に気になる。 そして、私のウェブサイトは「少なくて小さいファイル」でできているため、このもっさりが直撃してしまう。
PureBuilder Simply初期の動画でわかるが、Mimir YokohamaのウェブサイトがPureBuilder Simply化されたとき、Finishは63msだった。 これはConoHa VPS時代だ。 Chienomiも初期は今よりも文字が少なく、画像もなかったとはいえ、現在よりも速かった。 Chienomiは表示時間は1秒前後が常態化しており、私は強い不満を持っていた。
この「もっさり」はOsakaリージョンのインスタンス共通の問題で、Tokyoインスタンスでは発生していなかった。
とはいえメインサーバーの移転という大変な作業をするのは、なかなか踏み切れるものではない。
が、それでも辛抱できなくなってついに踏み切ったのだ。
インスタンス選定の計測タイム
単にOsakaからTokyoに移すだけでなく、折角なので同価格帯で選択肢になる構成をちゃんと検討することにする。 メインサーバーは約30USD/月の4GBメモリなので、これを基準にする。
例によってbenchmark-ballisticNG-video.mp4をxz -e -T$n -cで圧縮する。
| インスタンス | リージョン | -T0 |
-T1 |
|---|---|---|---|
| AMD High Perf | Osaka | 252.97s user 1.06s system 191% cpu 2:12.38 total | 275.81s user 1.20s system 99% cpu 4:38.41 total |
| High Freq | Tokyo | 244.56s user 0.53s system 198% cpu 2:03.22 total | 270.09s user 0.58s system 99% cpu 4:31.71 total |
| AMD High Perf | Tokyo | 284.59s user 0.82s system 196% cpu 2:24.89 total | 292.90s user 0.34s system 99% cpu 4:54.46 total |
| Intel High Perf | Tokyo | 257.35s user 0.55s system 195% cpu 2:12.25 total | 281.93s user 0.44s system 99% cpu 4:43.27 total |
どれもほぼ一緒だが、High Freqencyが少し速く、AMD High Performanceが少し遅い。 ちなみに、CPUは
- High Frequency - 3.8GHz Skylake (おそらくデスクトップ用?)
- Intel High Performance - 3.0GHz Cascade Lake Xeon
- AMD High Performance - 2.8GHz AMD (EPYC?)
であった。
意外なことに、ほとんどの場合High Frequencyが良いようだ。 AMD High Performanceは得手不得手が結構はっきり出る。
今回はIntel High Performanceがテスト時のウェブ応答時間が最も短かったため、Intel High Performanceを採用した。
マイグレーション
新しいインスタンスの準備
新しいインスタンスを作成し、基本環境を準備する。 私の場合、ファイアウォールグループの適用とPublic IPv6の追加がメイン。
まずはコンソールでログインし、/etc/ssh/sshd_configの編集。
ファイアウォール側でsshdのポート変更をしていない場合は(rootの鍵が登録できるので)最初からSSHでやっても大丈夫。
現在のVultrのArchlinuxイメージはufwが有効になっており、ルールによりsshも通らない。 今回のケースではポート制御はVultrのファイアウォールを利用するので、
systemctl disable --now ufwで止めてしまっていい。
インスタンスのアップデートをし、必要なパッケージをインストールする。 ユーザー作成やディレクトリ作成など、マイグレーションを行う前に必要な作業を済ませておく。
また、前回からの大きな違いとして、ArchlinuxのRubyはrubyが本体だけで、ruby-default-gemsとruby-bundled-gemsというグループパッケージに分割された。これらをインストールしないと、Rubyディストリビューションに本来含まれるものが含まれず話がややこしくなる。
じゃあそれをインストールすれば良いかというとそうではなく、実はruby-default-gemsが含んでいるのはruby-bundlerだけで、Default Gemを一括してインストールする方法はそもそも用意されていない。
ArchlinuxのRubyのメンテナンス状況はとても悪いのだ。
時刻関連も忘れずに
timedatectl set-timezone Asia/Tokyo
timedatectl set-ntp 1基本的な手順
今回はマイグレーションでの「コピー」は最小限にした。
前提として/etc/nginxと/etc/lighttpdはGitで管理していて、コピーする必要はない。
ただ、相対的に「コピーする必要性」は低い一方で、Gitで管理するほど緻密に内容を管理しているため、相対的に「コピーしても構わない内容」でもある。
基本的な方向性として、まずサイズが非常に大きいディレクトリをアーカイブしていく。
デスクトップ側で
ssh server socat -u TCP-LISTEN:55555 STDOUT > backup-foo.tar.zstのようにして、サーバー側は
tar cvf - . | zstd | socat -u STDIN TCP-CONNECT:localhost:55555という形でアーカイブにしていく。
今回の場合はファイル所有者等もpreserveしたいので、rootでtarにしていく。
少し難しい話になるが、アーカイブサイズを抑えるためにまず大きいディレクトリをアーカイブして消していきたいのだが、ダウンタイムを減らすため消すのが難しい場合もある。
この場合は--excludeするのを忘れないようにしたい。
ただし、このパートでは重複を避ける必要はあまりない。 あくまでアーカイブサイズを小さくしておくための措置だ。
絶対にとっておきたいのは/etc/letsencrypt。
これを保存しておかないと非常に面倒なことになる。
ウェブコンテンツである/srvも(個別にはGitで管理されているとしても)マイグレーションしたほうが良いが、私の場合/srv以下に一部アプリのデータも置いているためアプリケーションの停止が必要であるため順序に配慮が必要。
Dockerのボリュームを持っているディレクトリはアーカイブしたら消してしまったほうがいいが、消すためにはDockerの停止が必要で、Dockerを停止するということはDockerにルーティングしているものは503を返すようにしてからでないといけないので、こちらも順序が重要。
データ類はすべてvolumeとしてマウントされるタイプであれば/var/lib/dockerは消してしまってもいいが、OverlayFSだけで管理されているものが本当にないかをちゃんと確認してから。
こうしてひとつずつアーカイブしていき、動作させられる環境がアーカイブできたら新しいサーバーに移していく。
今度は逆でサーバー側で
socat -u TCP-LISTEN:55555 STDOUT | zstd -d | tar cvf -してからデスクトップで
ssh newserver socat -u STDIN TCP-CONNECT:localhost:55555 < backup-foo.tar.zstのようにする。
ちなみに、ここではzstdを呼び出しているけれど、GNU tarには--zstdオプションがあることはちゃんと知っている。
元サーバーを停止してから行っているのでないのなら一部のデータベースはマイグレーション作業を再度する必要がある可能性があるが、基本的にはウェブサーバー/ウェブアプリケーション(サーバー)/データベース/証明書は両方のサーバーに組んでも害はない。 DNSを切り替えることで無停止でマイグレーションすることもできる。 今回のメインサーバーの場合は多数のドメインをホストしているので、ひとつずつホストを切り替えることで順番にテストしながらマイグレーションできる。
今回のマイグレーション作業では、「忘れていたけれど必要なディレクトリ」であったり、「実は依存しているパッケージ」であったり、「実はそもそも現状で動いていない機能」だったりというのを洗い出しながら必要なものをコピーしたり、インストールしたりといったことを繰り返していく。
この過程で、外部ライブラリに依存しているRubyツールをBundlerを使うように変更した。
Docker
若干詰まった部分。
overlayfsがないぞって言われるのでfuse-overlayfsを入れたのだが、それでも動作せず、結局何が問題だったかというとカーネル更新後に再起動し忘れていたという。
さらに、fuse-overlayfsが邪魔になってしまって起動を妨げる。
なのでパッケージ削除しても/var/lib/docker/fuse-overlayfsが残ってしまうためやはり起動を妨げるのでこれを削除する、という流れになった。
サーバーといえどもカーネル更新後は再起動をお忘れなく。
Systemd
Systemdユニットのことは忘れやすいので注意が必要。
基本的には/etc/systemd/system以下にあるはずだが、これはサイトローカルなもの以外も入っているので、ちゃんと必要なものを導入し、ちゃんと動作するかテストして有効化するという手順が必要。
activeになるということだけでなく、動作が正常かどうかもちゃんと確認しよう。
ユーザーユニットを採用している場合はさらに忘れやすいので要注意。 ユーザーユニットの場合はそのままコピーで良いはずだが、動作確認はしよう。
ホスト切り替え
監視しているサーバーのホスト設定切り替えなどを忘れないように行う。
自動化している部分は結構忘れないように注意する必要がある。
最終バックアップ
一通りのマイグレーションが終わり、動作確認をし、DNS切り替えも済ませ、旧サーバーのサーバープロセスもシャットダウンする段階になったら、念の為にすべてをバックアップしておく。
ここでは重複は気にしないが、あまりに大きすぎるデータを抱えているディレクトリは予め消しておく。 この段階ではもう削除できるようになっているはずだ。 大きすぎるディレクトリを個別にアーカイブしたのはこれを安全にやるためでもある。
Dockerのデータがすべてvolumesで指定されており、安全にバックアップできたと確信しているなら/var/lib/docker/containersは消しておいてもいいが、こちらは消さずにこのバックアップに含めるのが安全。
私の場合はこんな感じ。rootで実行
rsync -avU --progress --exclude=home --exclude=run --exclude=proc --exclude=lost+found --exclude=sys --exclude=cache --exclude=swapfile --exclude=dev --exclude=srv --exclude=boot server:/ 20250804-fullsystem/使わないインスタンスはコスト的に消したいものなので、これをやっておくと後で後悔しない。
ついでにやったこと
NextCloudはあらゆる面で挙動がお行儀が悪いので廃止した。 結局のところ(LWMP over mTLSもあるから)なくても困らないというのも理由のひとつ。
これに伴ってSeafileを導入したが、長くなるのでこの話は別の機会に。
どうすごい?
微妙なチューニングの追加もしているが、インスタンス移転で10〜20倍程度速くなっている。
これはOsakaの問題だったので大した話ではないが、50ms、ロード自体は35ms程度というのはだいぶ狂っている。
一般に分かりやすいのが「阿部寛のホームページ」との比較で4倍速いということだが、それはバズ向けの言い方であり実際はそれ以上にすごい。
まず、ソースサイズはだいたい2倍くらいある。 Chienomiも画像が入っているし、文章量が多いのでサイズも大きいのだ。
そして、Chienomiのほうがレイアウト要素が多い。つまり、レンダリングコストが高い。
さらに何より、「阿部寛のホームページ」はHTTPS非対応、つまりHTTPなのである。 どちらのサイトもソースの数は6である。かつ、サイズも小さい。 これは重要なことで、HTTP/1.1で並列化される範疇である6であり、サイズが小さいことからHTTP/2による高速化の恩恵が小さく、TLS初期化のためのコストによるデメリットのほうが速度的には大きい。
が、それでも4倍。
そして、単なる4倍というだけでなく、40msを切るのは内容のあるウェブサイトとしてはかなり極限と言って良い。 しかも、VDSL環境での計測だ。
どうしたら速くなる?
実はやっていることは割と単純。
最初に十分な性能を持つサーバーを用意する。 パフォーマンス面もレイテンシ面も納得でき、かつ十分なメモリを持つインスタンスを用意しなければ工夫でどうにかならない。
まず、サイト自体は
- 必要最小限にする
- きれいな構造を保つ
- 不要な分割をしない
というような作りにしている。 minifyとかは基本的にしていないが、画像は小さくなるようにしているし、無駄なソースを増やさないようにもしている。 (JavaScriptファイルも、必要な場合のみロードする。)
結構細かく「この場合はこういうふうにしたほうがいい」という点はあるのだが、かなり多岐に渡るので解説はしない。 「ちゃんと知って理解していればこうすべきであることが分かる」の類のものが多い。
きれいな構造を保つのは、パースやレンダリングを速くするために結構重要。
なるべく速く他のソースのダウンロードを開始してほしいので、ここは気を遣った方が良い。
細かいテクニックを言うとCSSの定義はheadの中でも先に書いた方が良いが、それは余計なことをしていなければ本当に微差なので重要ではない。
そもそもの構成で「静的ファイルにビルドして(静的ファイル配信の速い)サーバーで配信する」という前提があるため、速くできる要素が結構少ない。 逆に言うと、そのように構成にすることが爆速配信のための入口になる。
静的ファイル配信の速いサーバーとしては私はNginxを採用している。 Linux Configによると実はLighttpdのほうが速いらしいのだが、
- 最前面にLighttpdを配置するのは結構大変
- Nginxと比べLighttpdはチューニングの余地が少ない
ということを考えるとNginxを置いたほうが良いと考えている。 本当に極限を目指し、そのために専用サーバーすら用意するのならばLighttpdでもいいかもしれない。
Nginxの設定は、基本に忠実に、公式に推奨される書き方で書く。 間違ってもrewriteや正規表現マッチングはしない。
プロトコルはHTTP/2が良い。 条件次第ではHTTP/1.1のほうが速いが、7ファイル以上あるソースだとHTTP/2の有利が大きいので、条件を限定的にしすぎないためにもHTTP/2がいい。 HTTP/3(QUIC)はすごく遅いので採用しない。安定して有利な用途のサイトが生まれれば使うこともあるかもしれないが、これまでのところ意義を見いだせていない。
ssl_session_*はチューニングどころ。
かなり重要なのがssl_ciphersでAES優先に並べることと、ssl_prefer_server_ciphers on;にすること。
AESを優先させることでAES-NIが効くようになってだいぶ速くなる。
だいたいそれくらいで、こうした積み重ねで速くできる。 「何かをしたから速くなる」ではなく、「ちゃんと本質的に必要なものに絞り込んで最適化しているから速い」なのである。
懸念点
High Frequencyでも起きていた問題なのだが、ある程度の転送をしているとサーバーから見てのダウンロードが停止してしまうことがある。
原因は全く不明だが、ひょっとしたらこれを理由に再度インスタンス変更をする必要があるかもれしない。 AMD High Performanceでは発生しなかったので、このためにAMD High Performanceに切り替えることもありうる。
コストを気にしないならDedicated CPUにしたいところではある。 また、Vultrはネットワークの問題が起きがちなのも気になっている。